Overview
Collaboration in science and research is essential for advancing knowledge, tackling difficult problems, encouraging innovation, and developing a more connected and influential scientific community. By collaborating, researchers can produce results that would be challenging or impossible to produce alone, thereby extending human knowledge and enhancing our comprehension of the world. Despite these benefits, there are numerous technical and administrative challenges that must be overcome before such a data-sharing endeavor can be regarded as acceptable and successful.
The JRA will help strengthen the inter-laboratory interaction of SIRFN members by facilitating the exchange of research data in a secure and efficient way. The creation of this data space seeks to overcome the technical barriers linked to data sharing, through common standards, tools and infrastructures in a context of digital sovereignty.
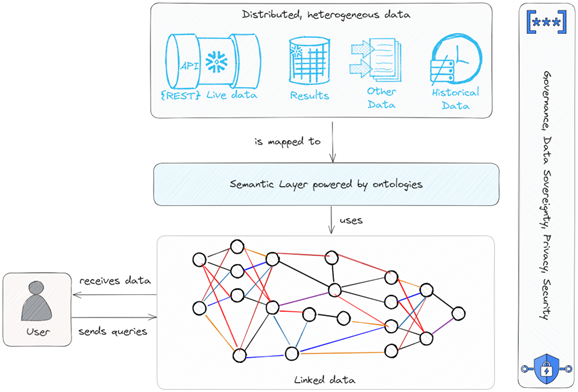
Objectives
The objective of this project is to build on top of the dataspace concept and develop an international research dataspace showcase where various participating research and industry partners can share and use research data.
Description
Sharing data in research has become an increasingly significant practice due to the multiple motivations and benefits of doing so.
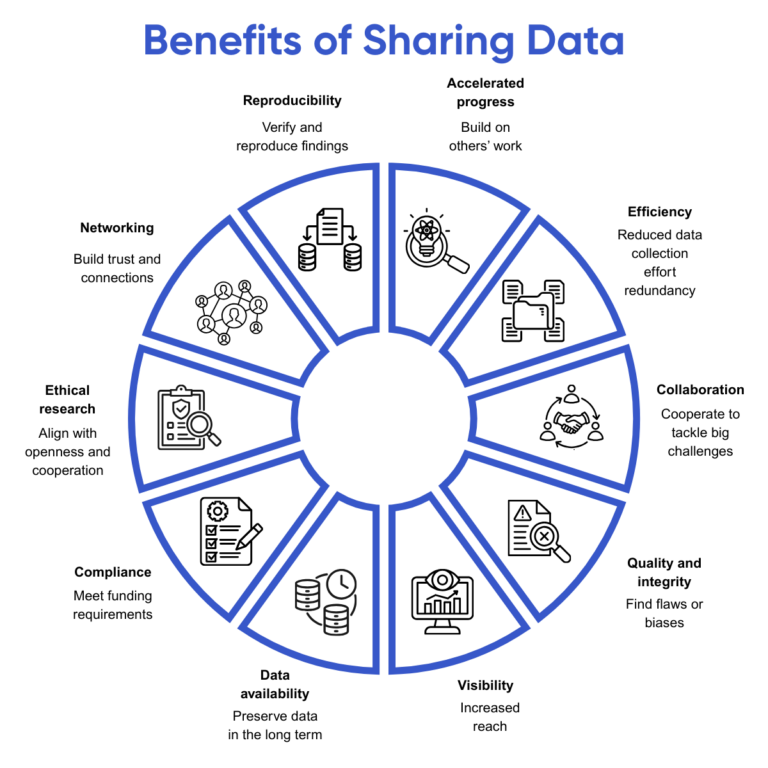
Despite these benefits, there are numerous technical and administrative challenges, such as data privacy and security concerns, the need for proper data management plans and documentation, potential data misuse, and the availability of trusted, simple, user-friendly methods and software tools. These challenges must be overcome before such a data-sharing endeavor can be regarded as acceptable and successful.
Dataspaces
Dataspace is a novel data-coexistence and sharing concept that treats data as a cohesive and integrated entity, regardless of its physical location, format, or source, and provides a higher-level abstraction that allows users and programs to access and interact with data seamlessly and conveniently. This contrasts with traditional data management systems where users must be aware of the structure/schema and physical location of data that they wish to access. These traditional approaches resulted in so-called data silos containing useful but isolated data that is hard to access or share due to upfront efforts.
The dataspaces concept aims to break these limitations by providing a more holistic view of data. Dataspaces assist in making use of the large number of heterogeneous data sources and comprehending their linkages while incurring a lower initial cost of semantic/schema matching. Apart from these technical advantages, dataspaces further simplify data administration and improve data accessibility by providing a single view of data, resulting in more effective data-driven decision-making and insights.
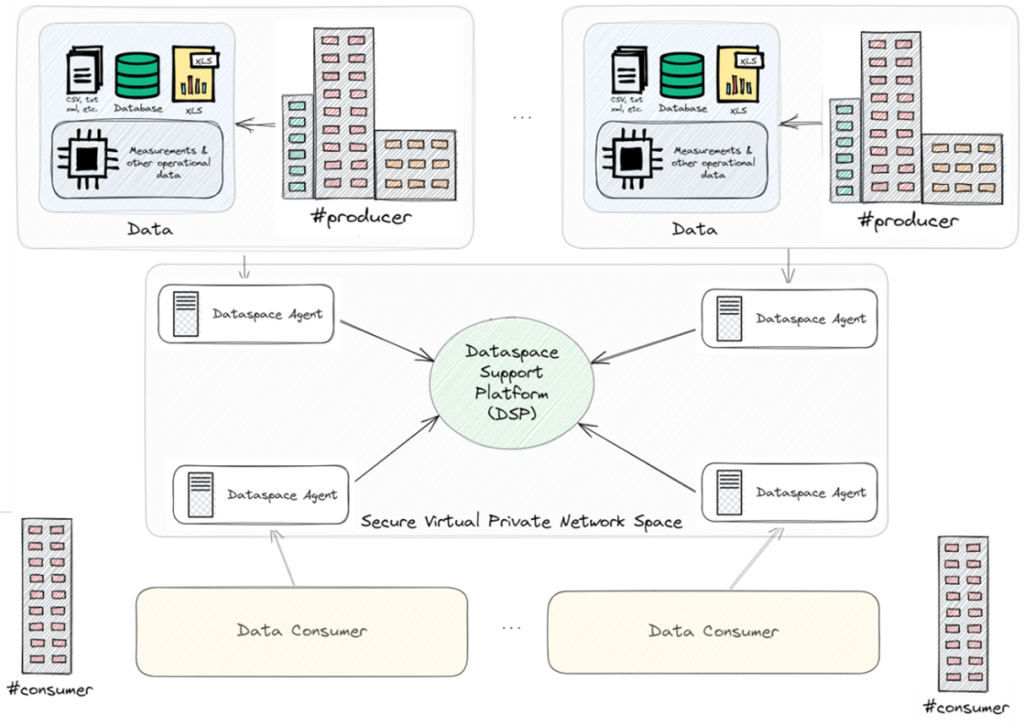
The figure presents an overview of the project idea and allocation architecture. Each involved partner will be given a computational device (interface agent) that will expose a number of data sources (producer) in different formats (CSV, XML, REST, plain text, DBMS, etc.). The data sources would provide data that the producer is willing to share and may include, but is not limited to, laboratory infrastructure and fact sheets, experiments and results, and historical data from various sensors, DERs, EVs, smart meters, etc. Each of the interface agents will be placed on the partner’s premises and will be connected to the internet.
Similarly, several consumer devices will also be set up and query these data sources. It is to be noted that the interface agent will have the capability to provide both the producer and consumer functionalities A dataspace support platform (DSP) will be hosted at AIT and provide the common dataspace service including discovery, registration, query, etc. A secure virtual private network will then be installed to create a secure space for these producer and consumer devices and the DSP. A UI will be developed for both the producer and consumers to have control over which sources to share and to query the data respectively. The DSP will use some well-know and domain-specific ontologies for automatic/semi-automatic schema/semantic matching when data sources are discovered/queried.
Tasks
- Requirements, conceptualization, and ontology development
- Software modules development
- Preparation of the hardware and central IT infrastructure
- Validation, verification, and deployment
Participants
Austria
Austrian Institute of Technology (AIT)
Denmark
Technical University of Denmark (DTU)
Germany
Fraunhofer IEE, TU Dortmund
Japan
National Institute of Advanced Industrial Science and Technology (AIST)
Switzerland
Zurich University of Applied Sciences (ZHAW)